|
Education
Fudan University
B.Eng. in Artificial Intelligence
Sep. 2022 – Present
No. 2 High School Attached to East China Normal University
High School Diploma
Aug. 2019 – Jul. 2022
Honors & Awards
- First-Class Scholarship for Outstanding Undergraduate Students, Fudan University, 2023-2024
- First-Class Scholarship for Outstanding Undergraduate Students, Fudan University, 2022-2023
- First Prize in the Preliminary Round of the Chinese Mathematical Olympiad (2021)
|
Experience
University of California, San Diego (UCSD)
Exchange Student
Sep. 2024 – Dec. 2024
|
|
[CVPR 2026] FlashPortrait: 6$\times$ Faster Infinite Portrait Animation with Adaptive Latent Prediction
Star
Shuyuan Tu, Yueming Pan, Yinming Huang, Xintong Han, Zhen Xing, Qi Dai, Kai Qiu, Chong Luo, Zuxuan Wu, Yu-Gang Jiang
webpage |
abstract |
bibtex |
arXiv |
code |
YouTube |
Bilibili |
Current diffusion-based acceleration methods for long-portrait animation struggle to ensure identity (ID) consistency. This paper presents FlashPortrait, an end-to-end video diffusion transformer capable of synthesizing ID-preserving, infinite-length videos while achieving up to 6$\times$ acceleration in inference speed. In particular, FlashPortrait begins by computing the identity-agnostic facial expression features with an off-the-shelf extractor. It then introduces a Normalized Facial Expression Block to align facial features with diffusion latents by normalizing them with their respective means and variances, thereby improving identity stability in facial modeling. During inference, FlashPortrait adopts a dynamic sliding-window scheme with weighted blending in overlapping areas, ensuring smooth transitions and ID consistency in long animations. In each context window, based on the latent variation rate at particular timesteps and the derivative magnitude ratio among diffusion layers, FlashPortrait utilizes higher-order latent derivatives at the current timestep to directly predict latents at future timesteps, thereby skipping several denoising steps and achieving 6$\times$ speed acceleration. Experiments on benchmarks show the effectiveness of FlashPortrait both qualitatively and quantitatively.
@article{tu2025flashportrait,
title={FlashPortrait: 6$\times$ Faster Infinite Portrait Animation with Adaptive Latent Prediction},
author={Tu, Shuyuan and Pan, Yueming and Huang, Yinming and Han, Xintong and Xing, Zhen and Dai, Qi and Qiu, Kai and Luo, Chong and Wu, Zuxuan},
journal={arXiv preprint arXiv:2512.16900},
year={2025}
}
|
|
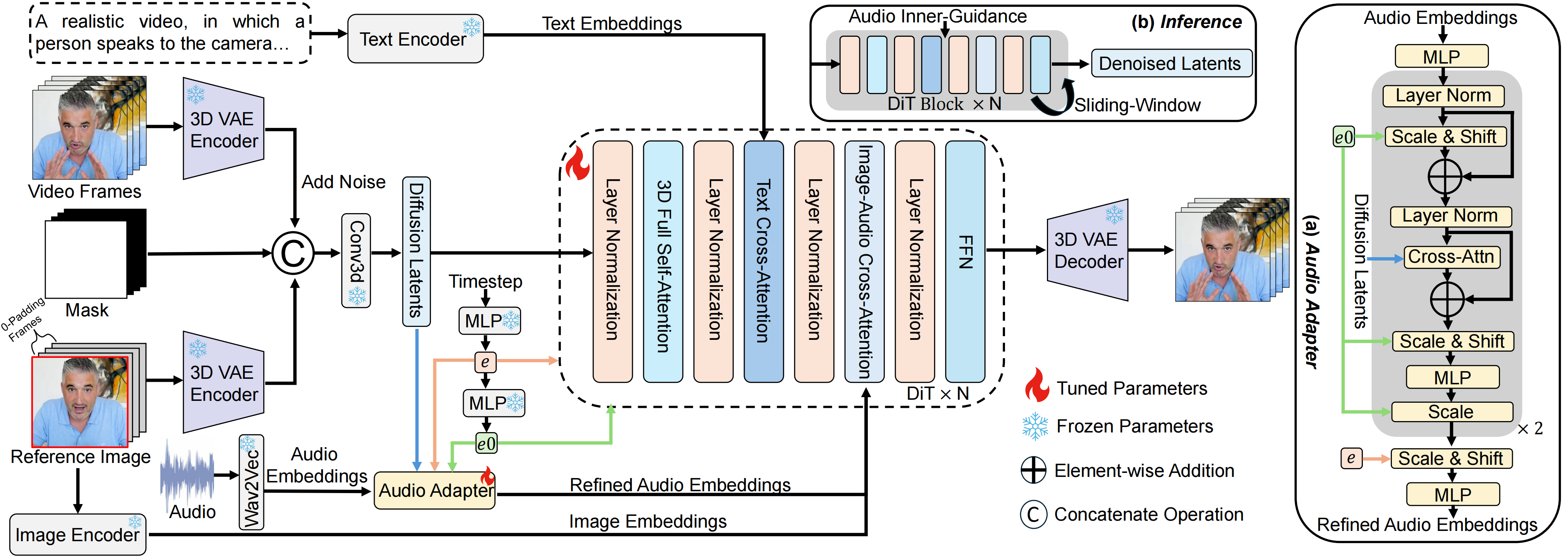
StableAvatar: Infinite-Length Audio-Driven Avatar Video Generation
Star
Shuyuan Tu, Yueming Pan, Yinming Huang, Xintong Han, Zhen Xing, Qi Dai, Chong Luo, Zuxuan Wu, Yu-Gang Jiang
webpage |
abstract |
bibtex |
arXiv |
code |
YouTube |
Bilibili |
机器之心 |
online demo
Current diffusion models for audio-driven avatar video generation struggle to synthesize long videos with natural audio synchronization and identity consistency. This paper presents StableAvatar, the first end-to-end video diffusion transformer that synthesizes infinite-length high-quality videos without post-processing. Conditioned on a reference image and audio, StableAvatar integrates tailored training and inference modules to enable infinite-length video generation. We observe that the main reason preventing existing models from generating long videos lies in their audio modeling. They typically rely on third-party off-the-shelf extractors to obtain audio embeddings, which are then directly injected into the diffusion model via cross-attention. Since current diffusion backbones lack any audio-related priors, this approach causes severe latent distribution error accumulation across video clips, leading the latent distribution of subsequent segments to drift away from the optimal distribution gradually. To address this, StableAvatar introduces a novel Time-step-aware Audio Adapter that prevents error accumulation via time-step-aware modulation. During inference, we propose a novel Audio Native Guidance Mechanism to further enhance the audio synchronization by leveraging the diffusion's own evolving joint audio-latent prediction as a dynamic guidance signal. To enhance the smoothness of the infinite-length videos, we introduce a Dynamic Weighted Sliding-window Strategy that fuses latent over time. Experiments on benchmarks show the effectiveness of StableAvatar both qualitatively and quantitatively.
@article{tu2025stableavatar,
title={Stableavatar: Infinite-length audio-driven avatar video generation},
author={Tu, Shuyuan and Pan, Yueming and Huang, Yinming and Han, Xintong and Xing, Zhen and Dai, Qi and Luo, Chong and Wu, Zuxuan and Jiang, Yu-Gang},
journal={arXiv preprint arXiv:2508.08248},
year={2025}
}
|
|
